

As businesses increase the volume of data they collect and use, machine learning (ML) and other artificial intelligence (AI) tools become ever-more crucial for scaling workflows. By combining intelligent algorithms with data through machine learning tools, businesses can turn data into insights. These tools enable data-driven business decisions as well as the ability to build and deploy custom solutions at scale.
In order to ensure consistency and accurate results, machine learning models are trained on a steady state, non-changing set of data. ML models in Snowflake are run as user-defined functions (UDFs) out of Snowpark – Snowflake’s API engine. Once a UDF is created and running in production, all logic and code within the UDF do not change unless it is manually altered. If there is data drift (unexpected or undocumented changes to data structure, semantics, and infrastructure), the goal of the model has changed. In other words, you must retrain the ML model.
Pipelines, such as Snowflake Native Pipelines, orchestrate the whole machine learning lifecycle, from training to deployment, while reducing workflow complexity. Hakkoda’s Snowflake Native Pipelines handle the deployment, execution, and scheduling of a pipeline (or DAG) entirely in Snowflake, eliminating the need for third-party SaaS tools. However, when needed, Hakkoda’s Native Pipelines can easily sync/integrate with third-party tools. With the release of Snowpark Python Support, it’s also possible to create pipelines using tasks and stored procedures.
Starting Machine Learning Retraining
Model retraining refers to updating a deployed machine learning model with new data. Retraining many become necessary when onboarding a new company, when the source data changes, or when data drifts. Traditionally, retraining has always had to be done manually. However, Hakkoda’s data experts have developed alternative options, including “human-free” and “human in the loop” automation to monitor, notify, and retrain a model (UDF), all running natively in Snowflake.
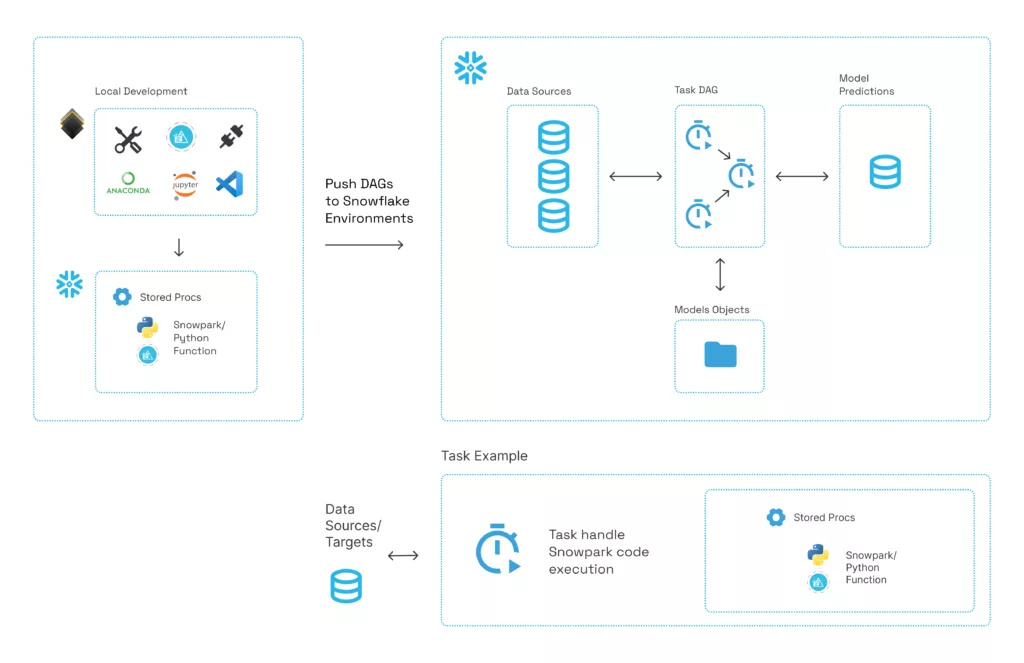
To enable automated model re-training, Hakkoda leverages Snowflake tasks and stored procs to create two DAGs: one DAG for the training pipeline and the other DAG for the inference pipeline. Preprocessing stored procedures from the training pipeline are re-used in the inference pipeline on the incoming data to keep the processing logic consistent between the training and inference pipelines.
These pipelines are made up of tasks, streams, stored procedures, UDFs, and tables. This allows Hakkoda clients to holistically leverage their Snowflake platform and reduce security risks by keeping all of the data in Snowflake.
Drift Monitoring and Machine Learning Retraining
Organizations can use Hakkoda RM, a resource monitoring and observability service built for Snowflake customers, as an automated optimization approach to drift monitoring. In the case of data drift detection, a stream and task on a drift monitoring table tracks when the drift detection metrics fall outside of a desired threshold.
The drift baseline threshold is determined by a stored proc either in the training pipeline or in its own pipeline that captures the initial distribution of the data. If the calculated drift in the inference pipeline falls outside of the desired drift threshold, new metrics are pushed to a table that captures them. A stream then triggers a task that can either send an alert through an external function for human in the loop re-training, or the task can trigger the training pipeline for human-free automation. This gives the users flexibility to determine their re-training strategy based on specific use cases.
If the model does not meet the performance thresholds defined in the evaluation step, the model used for inference will be rolled back to the previous version. Also, note that this approach assumes that eventually, additional ground truth data will be added to the original training datasets.
Dealing with Data Change
In a scenario in which source data changes or a company needs to onboard a new customer, the training pipeline can be easily pointed towards new datasets and re-training can be executed by manually running the training pipeline.
Alternatively, since the underlying data is changing, the drift detection task will trigger and re-train the pipeline. However, when changing the data source it is highly recommended to perform an EDA on the new dataset, and review the newly trained model metrics before deploying the inference pipeline.
Automate with Hakkoda
Automating machine learning retraining not only saves time and man-power, but it allows for real-time adjustments to be made, keeping your ML accurate and on task. Snowflake was designed from the ground up to support machine learning and AI-driven data science applications.
By partnering with Hakkoda, a Snowflake Elite Services partner, you not only can bring data-driven innovation, automation, and new opportunity to your business, you can access state-of-the-art solutions, accelerators and tools that support you and your business throughout your data innovation journey. Contact a Hakkoda data expert today to begin automating your ML retraining in Snowflake.


