

Snowflake has a lot of great data science tooling in Snowpark. However, ease of development and development complexity can prevent data scientists from taking full advantage of new workflows enabled by Snowpark. One such workflow is Snowflake Native Pipelines. Snowflake Native Pipelines handle the deployment, execution, and scheduling of a pipeline (or DAG) entirely in Snowflake. This new approach to Snowflake pipelines drastically reduces the complexity of creating data science pipelines entirely in Snowflake.
In this post I’ll cover how we reduce the complexity of this workflow, why you would use Snowflake native pipelines, and the limitations.
Creating Data Science Pipelines: An Overview
Snowflake Native Pipelines is an architecture created to deploy data science pipelines directly to Snowflake. The pipelines can orchestrate the whole machine learning lifecycle, from training to deployment, and all of this is done within Snowflake. Creating pipelines using tasks and stored procedures has been possible since the release of Snowpark Python Support.
However, there is a significant overhead if a data scientist is creating these pipelines by hand. In the Snowflake Native Pipelines architecture, Kedro, an open-source Python framework, is used to dynamically create the Snowflake task DAG. Such a streamlined approach helps developers and engineers create pure Snowflake pipelines.
The diagrams below outline the workflow for using Kedro native pipelines:
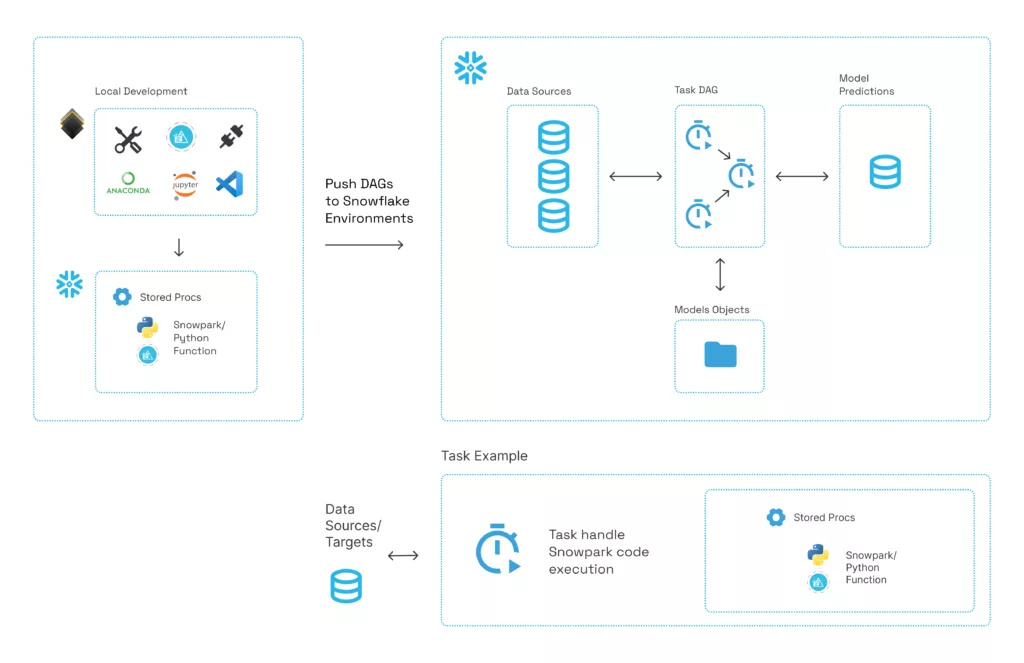
In the diagram above, stored procedures are created when the Kedro project runs. Then, a task DAG (Directed Acyclic Graph) definition is created, which can be executed to create the Snowflake task pipeline. Tasks pass processed data to each other by reading and writing from tables. Snowflake stages can be used to save non-tabular objects, like models. In the “Task Example” from Figure 1, Kedro automates wrapping the stored procedure in the task, and the Python/Snowpark code is wrapped in the stored procedure.
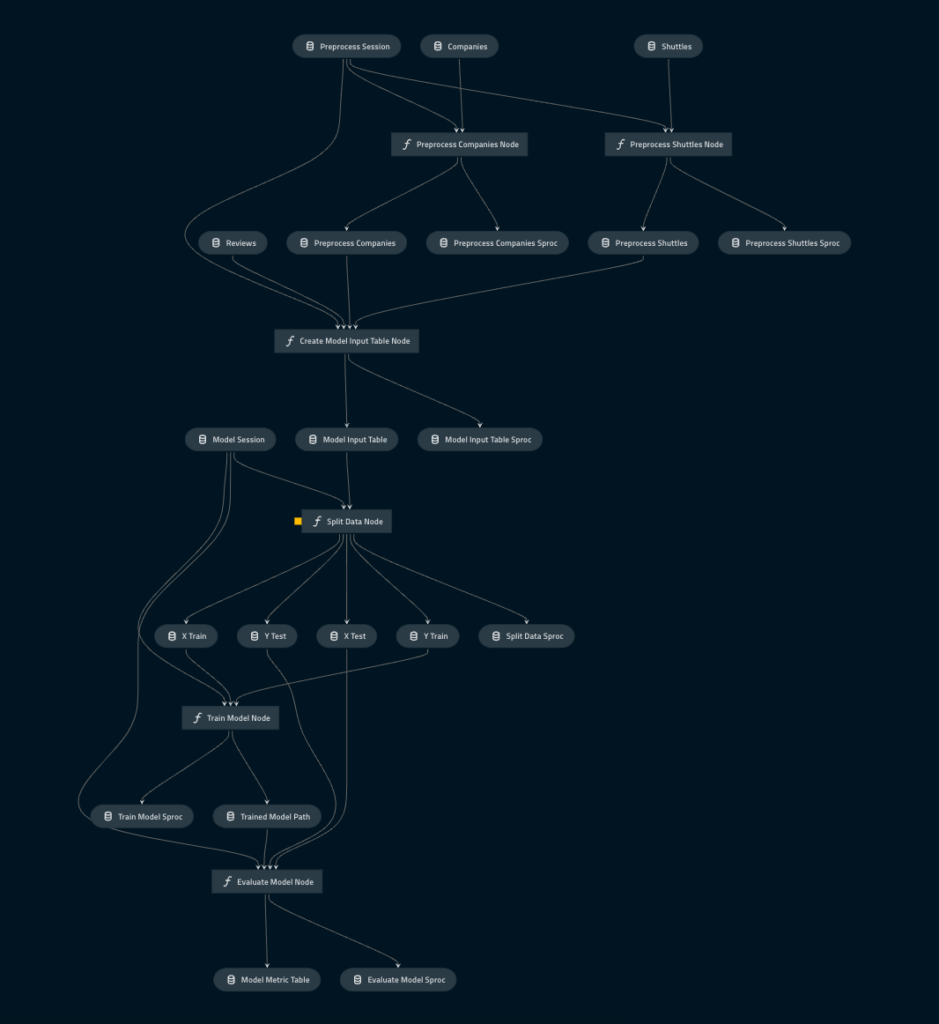
The Kedro DAG is created as part of the model development process. Snowflake session objects are passed to each function to mimic execution in Snowflake, since the Snowflake session is passed to the stored procs when deployed. Parameters can also be passed as dictionary inputs to the stored procs. Every dataset created will exist in Snowflake so they can be created/accessed by the Snowflake task DAG.
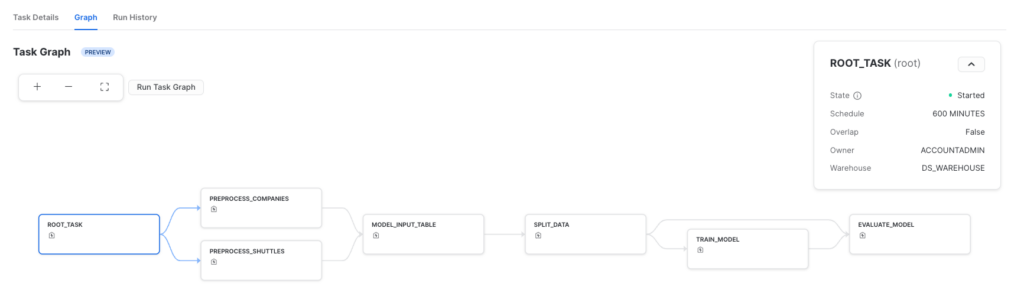
The generated Snowflake task definitions can then be deployed to Snowflake. The root task dictates the schedule for when the DAG is executed. It is an automatically generated empty task since Snowflake tasks cannot have multiple starting tasks.
Leveraging Snowflake Native Data Science Pipelines
Snowflake Native Pipelines unlock new potential for speeding up machine learning development. The biggest benefit of using them is that there is no need to spin up additional infrastructure. Since Snowflake Native Pipelines run using stored procedures and user-defined functions (UDFs), there is no need to manage and deploy Docker containers.
Furthermore, you don’t have to use a scheduler such as Airflow because all scheduling can be handled by Snowflake tasks. This also allows permissions to be managed through Snowflake so you can leverage your existing Snowflake RBAC model instead of setting up new permissions on another tool. These benefits reduce IT overhead and make it easier for data scientists to bring their models to production.
Other Factors to Consider As You Build Data Science Pipelines in Snowpark
Snowflake Native Pipelines assume all of the data is already in Snowflake and Snowflake stored procs don’t have access to the public internet. Therefore, any Snowflake pipes should be set up to bring in data from outside of Snowflake before developing the native pipelines. Without access to the public internet, no APIs can be set up in Snowflake for model inference. This means all inference needs to be done in Snowflake.
Also, because Snowflake works best with tabular data, it’s not recommended to do image processing tasks using Snowflake Native Pipelines. Snowflake doesn’t support the use of GPUs (yet!), so the platform won’t be able to provide the computer for more intensive tasks like image processing. Again Snowflake stored procs don’t have multi-machine support, so very compute-intensive modeling should be done elsewhere.
How Hakkoda Uses Snowflake Native Pipelines
While Snowflake Native Pipelines may not cover all of your data science use cases, they have a lot to offer as far as reducing infrastructure overhead and simplifying your data science stack. At Hakkoda, some of the solutions we’ve created have enabled our teams to easily create native pipelines and other solutions that help data scientists and engineers with their projects.
Our SnowPro certified expert data teams use the latest technology and constantly create new solutions to make your data projects effective and seamless. Our scalable team approach will guide you throughout the entire journey, recommending the most effective solution for your needs.


