

In the ever-evolving landscape of data management, organizations often find themselves grappling with complex data pipelines that are cumbersome to maintain, prone to errors, and simply out of date.
The challenges posed by this complexity are especially evident with regard to large supply chains, where the intricacies of managing vast amounts of data can compound along the path from manufacturing to distribution. For example, minor errors in inventory data can lead to over- or understocking a particular store or region, disrupting the delicate balance of supply and demand. Such errors can also result in misinformed decisions, impacting everything from production schedules to delivery timelines.
The dynamic nature of supply chain operations underscores the critical need for streamlined and up-to-date data management to ensure precision, reduce inefficiencies, and fortify the resilience of the entire supply chain ecosystem. With these objectives in mind, Hakkoda recently helped one major food distributor company embark on a journey to modernize its data pipeline, moving from a convoluted and error-prone setup to a streamlined and automated system.
The Old Data Stack: Data Pipelines Trapped in a Web of Complexity
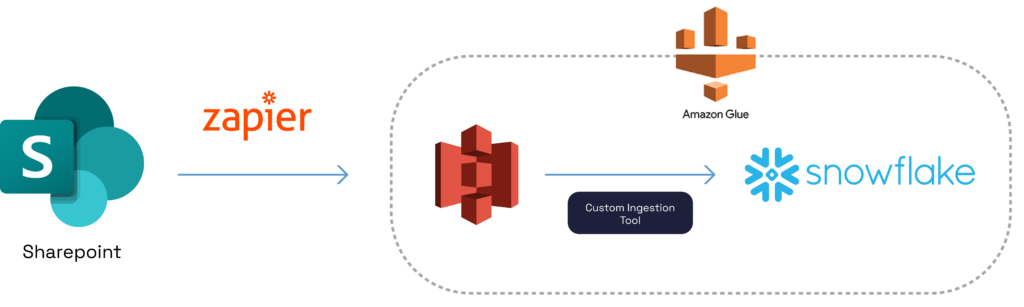
The company’s previous data stack consisted of a web of interconnected tools and manual processes. Here’s how it worked:
- Data Source: Data comes in the form of CSV or Excel files, which get manually uploaded to a Sharepoint folder.
- Zapier: To ingest data from Sharepoint, Zapier is used to periodically check the Sharepoint folder for new files every 15 minutes. When new files are detected, Zapier initiates the ingestion process from the Sharepoint folder into a designated AWS S3 bucket.
- Custom Tool for Data Ingestion: Once the files arrive in the S3 bucket, the company’s custom tool first performs transformations on the files to ready them before loading them into the Snowflake Data Cloud. One of the transformations includes converting Excel files, if there’s any among the incoming files, into CSV files. This tool contains various helper functions, including one that optionally runs Stored Procedures for data transformations, once data arrives in Snowflake.
- Loading into Snowflake: The process of loading data into Snowflake, any transformations on the files prior to loading as well as any Stored Procedure runs are orchestrated by an AWS Glue job. However, this custom tool requires manual addition of a new record in a config table in Snowflake for each new file, which complicates the process. The config table stores configuration details in a JSON format. Additionally, if any of the source files are of Excel type with multiple sheets, the names of those sheets need to be explicitly specified in the config table.
This data stack not only involved multiple tools, but also required frequent manual intervention, making it susceptible to errors and challenging to maintain.
The New Data Stack: Simplicity and Automation for Data Pipelines
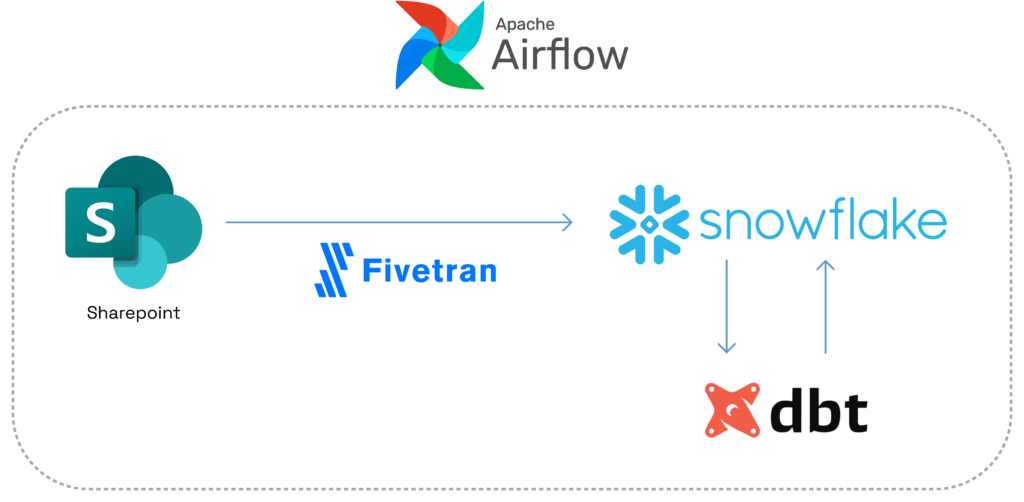
Recognizing the need for a more efficient end-to-end analytics from source to reports, this large organization connected with Hakkoda to create error-resistant data pipelines by transitioning to a new data stack, including:
- Fivetran for Data Ingestion: Instead of relying on Zapier, the company now utilizes Fivetran, a data integration platform. Fivetran automatically ingests CSV or Excel files as soon as they are uploaded to the Sharepoint folder.
- dbt for Data Transformation: With the new data stack, the data freshly deposited into Snowflake by Fivetran is processed by dbt, a popular data transformation tool. dbt automates the transformation process, reducing the need for manual intervention.
- Airflow Orchestrates the Process: Apache Airflow, a powerful workflow automation tool, orchestrates the entire end-to-end process. It ensures that data is ingested, transformed, and made available for analysis seamlessly.
The Benefits of Streamlining Data Pipelines in the Modern Data Stack
The shift from the old, complex data stack to the new one has brought about several notable benefits:
- Simplicity: The new stack is far simpler, with fewer tools and manual steps involved. This simplicity translates into easier maintenance and reduced room for error.
- Automation: Automation is a key highlight of the new data stack. Once configured, the entire pipeline runs automatically, eliminating the need for frequent manual actions and interventions.
- Error Identification: In the old stack, pinpointing the source of errors was a daunting task due to its complexity. With the new stack, the streamlined process makes it easier to identify and resolve errors promptly.
- Configurational Ease: Unlike the old stack that required manual additions to a config table for each new file, the new stack automatically detects and ingests all files in the specified Sharepoint folder, simplifying configuration management.
Streamlined Data Means Better Business
Hakkoda’s work with the large food distributor above, who transitioned from a complex and error-prone data stack to a streamlined, automated one, highlights many of the benefits of modernizing data pipelines.
Simplicity, automation, and ease of maintenance have significantly improved the client’s data management practices after their transition, setting the stage for more efficient and reliable data-driven decision-making across their supply chains. With a strong data strategy in place, the client is also ready to pursue further data innovation.
Modernizing Your Data Pipelines with Hakkōda
As the ever-turbulent data landscape continues to evolve, it will only become more urgent for businesses to embrace new data strategies that leverage the modern data stack to stay competitive and agile in the ever-changing market.
Hakkoda is a modern data consultancy built for the explicit purpose of harnessing the power of data, helping our clients drive actionable insights and lead the charge for business innovation. We believe that data innovation is built on the right talent working in the right technology stack, and our data teams are certified across a wide range of modern data tools, platforms, and services, including dbt Cloud, Fivetran, Apache Airflow, and many more.
From Snowflake migrations, to BI modernization, to laying the foundations for your organization’s first deployments of generative AI, the Hakkoda team is your partner in driving better business solutions anchored in quality data strategies. Need support for your next big data project? Let’s talk.


