

Many enterprises still rely on secondary vendor tools and fragmented solutions that create unnecessary complexity in their data stack. This patchwork approach forces teams to manage multiple technologies, each with distinct interfaces, security models, and operational requirements.
Common issues with fragmented ingestion:
- Multiple vendors for ingestion, storage, and processing increase operational overhead
- Different interfaces and skillsets required for ingestion vs. analytics
- Custom integrations break with schema changes or scaling demands
- Lack of unified governance, observability, or central control across the data pipeline
- Security and compliance gaps when data moves between separate vendor systems
- Limited visibility when data crosses vendor boundaries
Business impact: slowed data delivery, rising operational complexity, and reduced trust in analytics.
How Snowflake Openflow Helps Alleviate These Pain Points
Snowflake Openflow eliminates this fragmentation by handling ingestion natively across your entire data landscape—whether you’re working with structured databases, unstructured content, or semi-structured streaming data. Instead of different tools for different data types, you get one platform that adapts to your sources.
Built on Apache NiFi and integrated directly into Snowsight, Openflow provides a low-code canvas for building data pipelines without separate infrastructure or custom scripts. Key benefits include:
- Security & governance: Uses Snowflake roles, policies, and credentials—no separate secret store to manage
- Flexible deployment: Pick what fits your team: BYOC (customer-managed VPCs) or SPCS (Snowflake-managed infrastructure and scaling)
- Clear split of duties: Build/monitor/troubleshoot in the Openflow Canvas (Data Plane). Manage deployments and browse connectors from a single Control Plane view in Snowsight
- Billing & observability in one place: See pipeline health, usage, and costs right next to your Snowflake compute and storage
- Developer-friendly: Add custom logic with scripting processors, and plug into Streams, Tasks, and Snowpark when you need it
Below, we’ll walk through complete implementations across three common data patterns: structured data from SQL Server, unstructured content from Slack, and semi-structured streams from Kinesis and DynamoDB. Each demonstrates how native ingestion simplifies what used to require multiple vendor solutions.
For detailed setup and configuration steps, see our comprehensive Openflow implementation guide.
Streamlined Implementation with Snowflake Openflow
Before diving into specific implementation scenarios, it’s essential to understand Openflow’s architecture and the foundational concept of runtimes. The diagram below illustrates how Openflow operates within your Snowflake environment, showing the relationship between the Control Plane (management interface), Data Plane (processing canvas), and your various data sources. This architecture scales consistently across all your ingestion needs.
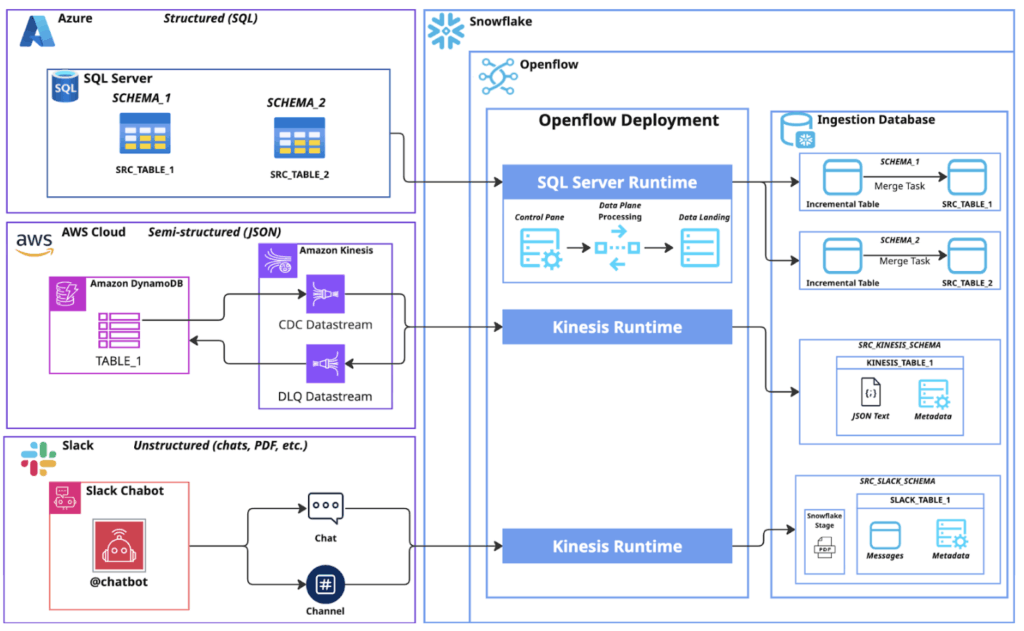
Runtimes are the execution environments that power your data pipelines. You’ll create dedicated runtimes optimized for each data source type – whether connecting to structured databases, processing unstructured content, or handling streaming data.
Each runtime provides the specific compute resources and connector capabilities needed for its designated data patterns.
Openflow offers simple, ready-to-use connectors that make setup fast and straightforward across all source types.
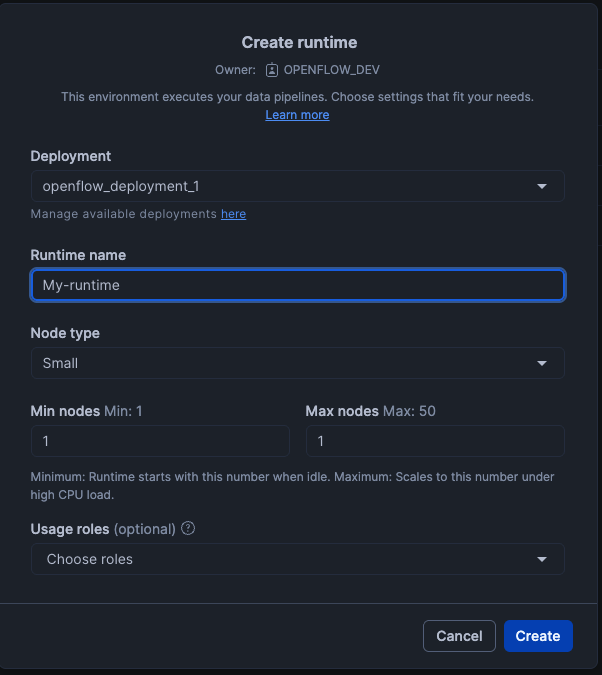
The process begins the same way for any connector: launch the Openflow instance from Snowsight. And then create a Runtime:
Now select the desired out-of-the-box connector:
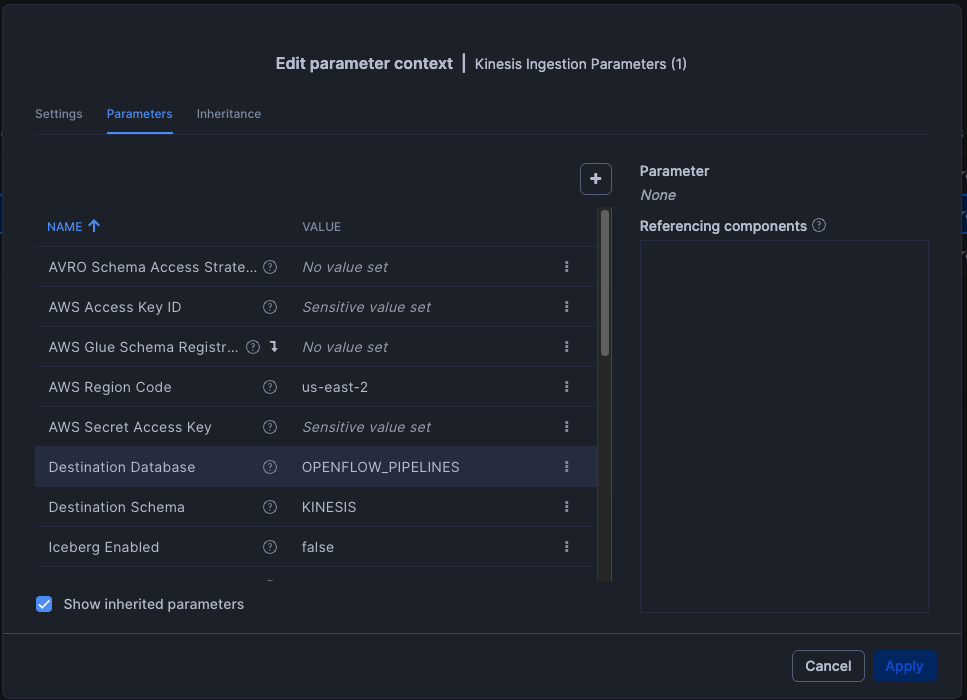
Then, provide the necessary credentials and parameters to establish a direct connection between the source and Snowflake through Openflow, e.g.:
Once everything is configured, simply right-click on the connector and select Run to start the ingestion.
Implementation Scenarios
Up to this point we’ve covered what all OpenFlow connectors share. Below, we outline the particular configurations and behaviors unique to each connector.
Structured Data – SQL Server
Features:
- The connector requires basic setup in SQL Server (enable Change Tracking).
- Ingestion: define which tables to include (by name, regex, or JSON filters) and the merge frequency (CRON schedule).
- Some parameters are optional, but at least one table selection method must be provided.
- Result in Snowflake: replication of SQL Server schemas and tables, with journal tables for incremental changes, plus streams used by tasks to manage merges into the target tables.
Workflow:
The connector is organized into three process groups that handle the logic for Snapshots, Incrementals, and Snowflake Streams validation
- Snapshot Process Group
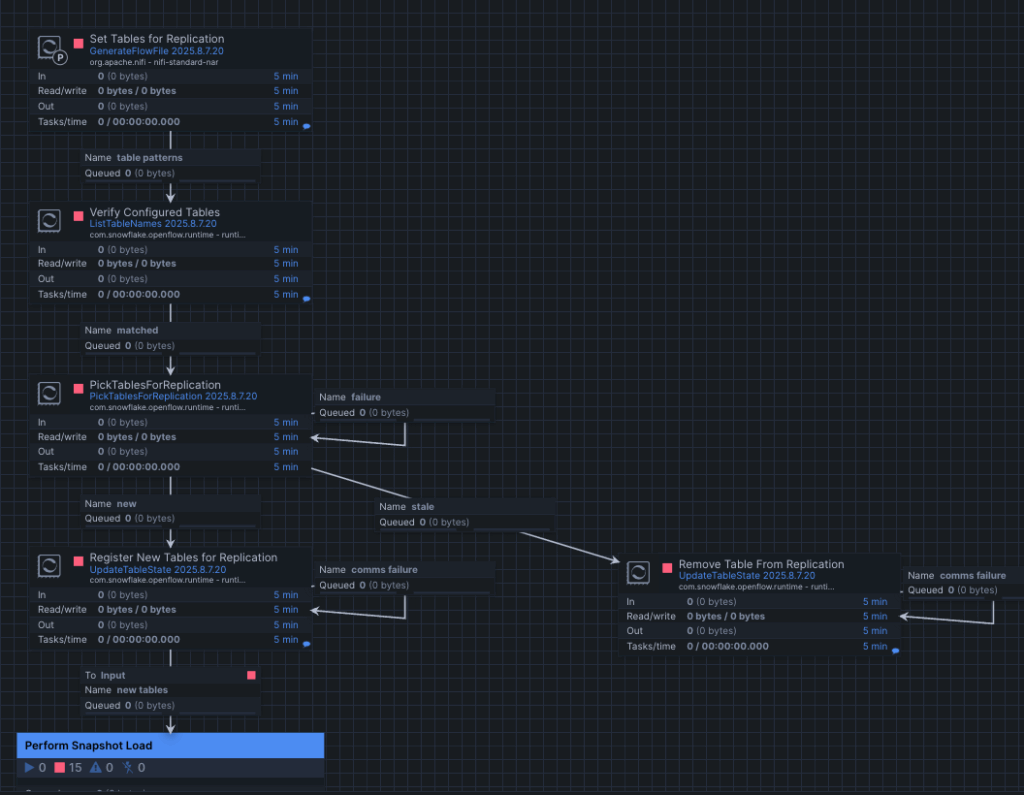
This process group is responsible for managing the initial replication setup for SQL Server tables into Snowflake. This workflow defines which tables should be replicated, keeps the replication list up to date (adding or removing tables as needed), and then runs the initial snapshot load. During the snapshot, it prepares the schema in Snowflake, ingests the full source data, and finalizes the setup so the connector can switch smoothly into incremental replication.
- Incremental Process Group
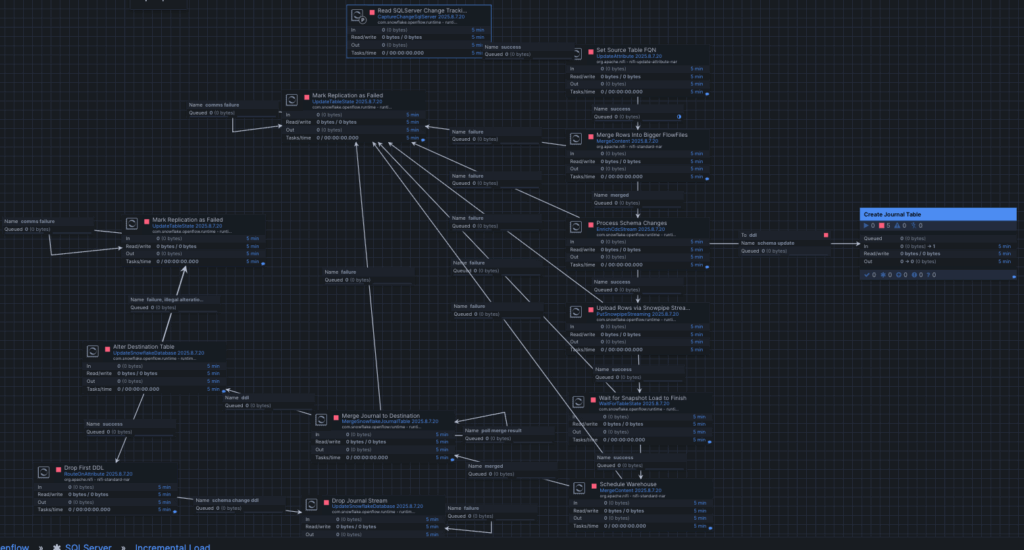
This workflow handles the ongoing replication of changes from SQL Server into Snowflake. It continuously captures new changes using SQL Server Change Tracking, processes schema updates if needed, and streams rows into Snowflake through Snowpipe Streaming. Updates are stored in journal tables to preserve a history of changes, while merge operations keep the target tables aligned. In short, this process group ensures that once the snapshot is complete, the data in Snowflake remains continuously synchronized with the source.
- Snowflake Streams validation
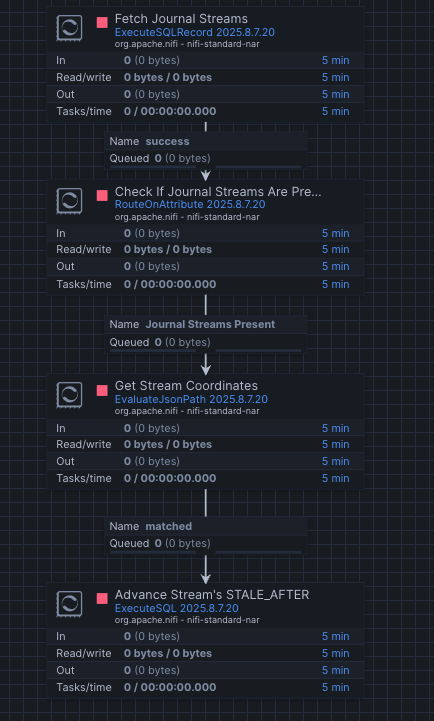
This workflow ensures that the journal streams in Snowflake remain active and aligned with the incremental ingestion. It periodically validates the state of each stream, retrieves their coordinates, and advances them when necessary to avoid staleness. In short, this process group guarantees the health and continuity of change tracking so incremental loads can keep flowing smoothly.
Semi-structured Data – AWS Kinesis
Features:
- AWS setup (IAM, Kinesis, DynamoDB): You’ll touch IAM for access, Kinesis for the stream, and DynamoDB for checkpoints. If you’ve done basic AWS before, you’ll be fine.
- Message formats (JSON & Avro): JSON is the simplest starting point. Avro is optional, but if selected for schema control, it must be paired with AWS Glue Schema Registry.
- Ingestion into Snowflake: Point the connector at your target database and schema, then it creates the table for you—no hand-written DDL.
- Near-real-time freshness: Events show up in Snowflake in seconds. Adjust one batch setting to choose “faster” or “cheaper.”
Workflow:
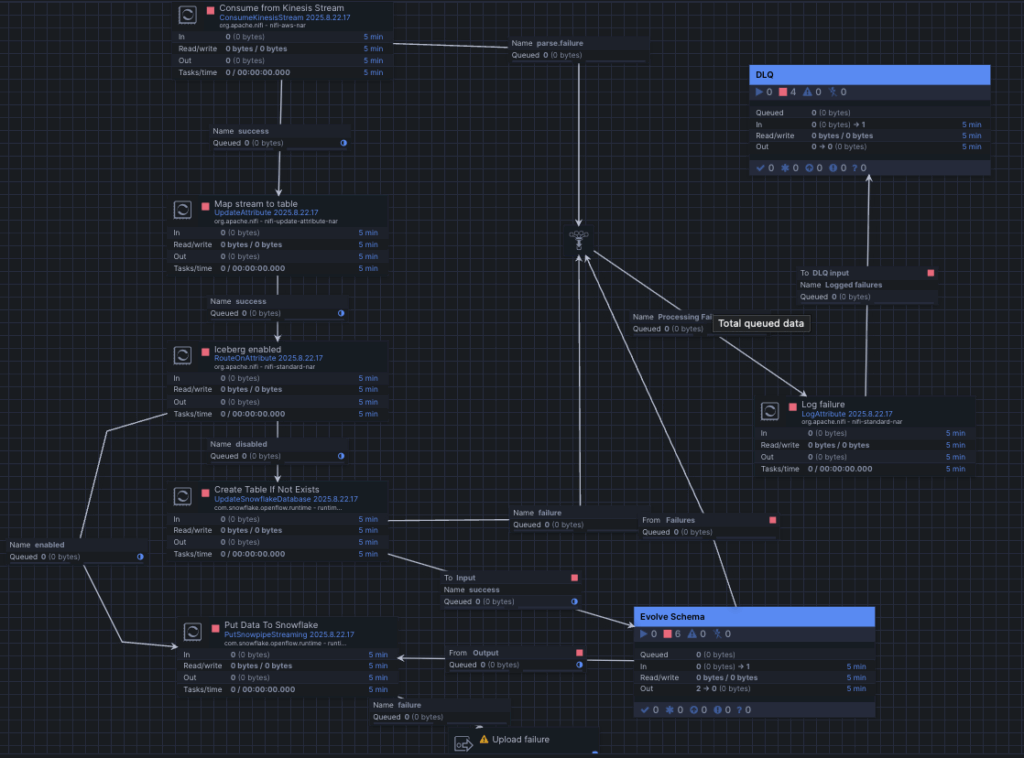
For the Kinesis connector, everything runs inside one process group called Amazon Kinesis. This group reads events from Kinesis and streams them into a Snowflake table. It also checks optional settings like Map Stream to Table and Iceberg Enabled. If the table doesn’t exist, it creates it. If schema evolution is on, it updates the table (adds new columns) before loading the data.
Unstructured Data – Slack
The Openflow Slack Connector integrates a Slack workspace with Snowflake, enabling ingestion of messages, reactions, file attachments, and channel memberships (ACLs). It also supports Snowflake Cortex Search, preparing Slack data for conversational analysis in AI assistants through SQL, Python, or REST APIs.
Features:
- Ingest Slack data: Continuously capture messages, reactions, files, and membership lists into Snowflake for centralized, searchable insights.
- Cortex-ready: Prepare Slack content for natural language querying and conversational search, respecting Slack channel ACLs.
- Private channels support: By inviting the Slack App Chatbot to private channels, membership lists are automatically refreshed and stored.
- Flexible use cases:
- Analytics only: Ingest Slack data without enabling Cortex for custom reporting and analysis.
- Analytics + Cortex: Ingest Slack data and activate Cortex for AI-powered conversational search.
Workflow:
This connector is organized into three process groups: Init Tables, Ingest Messages and Snapshot Slack members
- Init Tables
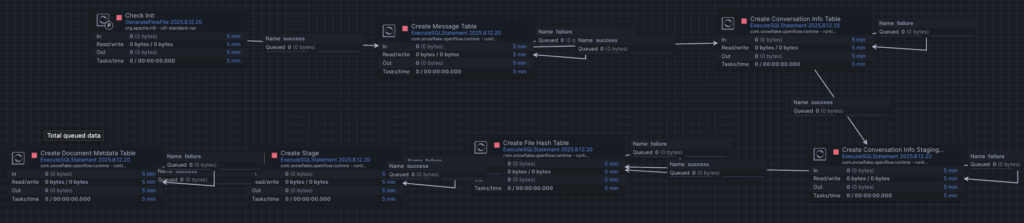
This process group prepares the Snowflake environment so the connector can run properly. It creates the necessary metadata objects (tables for messages, conversation info, file hashes, staging, etc.) and configures supporting structures like stages. In short, it sets up the foundation for reliable ingestion and change tracking before snapshots and incremental loads start running.
- Ingest Messages
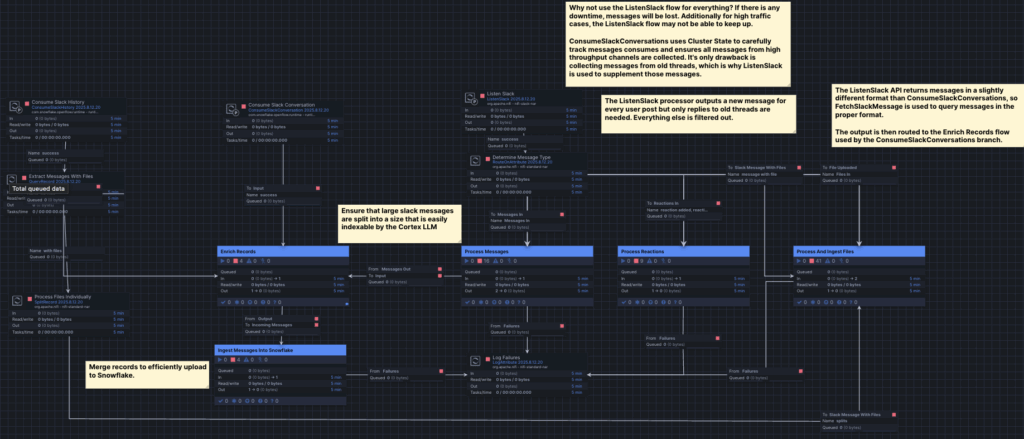
This workflow ingests Slack conversations, including messages, reactions, and attached files. To handle different workloads and formats, it combines two approaches:
- ConsumeSlackConversations ensures reliable capture of high-throughput messages using cluster state, minimizing data loss.
- ListenSlack complements this by picking up additional messages, though it is more sensitive to downtime.
The flow processes and enriches the raw messages, splits large ones into smaller chunks for efficient indexing, and merges records before uploading them to Snowflake. Attached files follow a dedicated sub-flow, where they are extracted, processed, and ingested individually.
Overall, this design ensures Slack data—messages, files, and reactions—are consistently normalized and stored in Snowflake for downstream analytics.
- Snapshot Slack members

Finally this group captures Slack membership snapshots (users and conversations) and versions them with a timestamp. Each run records a fresh snapshot, stages the data, and merges it into Snowflake.
The design includes optimizations like batching and merging records to minimize redundant SQL operations while keeping latency low. Once a new snapshot is safely recorded, older snapshots can be cleared to maintain efficiency.
Summary: Snowflake Openflow for Strategic Data Operations
Traditional data ingestion creates operational complexity through vendor fragmentation: multiple tools, interfaces, and security models that slow data delivery and increase maintenance overhead. Snowflake Openflow consolidates ingestion natively within your data platform, eliminating secondary vendors while accelerating business outcomes.
Core Business Value:
- Faster time-to-insight: Reliable, native pipelines eliminate ingestion bottlenecks that delay analytics and reporting. Data flows directly from source to analysis without vendor hand-offs or custom integration delays.
- Reduced engineering overhead: Teams spend less time maintaining brittle connections or troubleshooting DIY scripts. Built-in connectors and unified monitoring reduce operational complexity across structured, unstructured, and semi-structured data sources.
- Compliance and auditability: Native integration with Snowflake’s governance framework provides centralized audit trails and policy enforcement. No separate security models or credential stores to manage across vendor boundaries.
- Scalability for AI/ML: Strong, unified data foundation supports advanced analytics, search, and machine learning initiatives. Native integration with Snowpark and Streams enables seamless progression from ingestion to AI workloads.
- Future-proofing: Flexible architecture adapts to new data sources and scaling demands without architectural redesign or additional vendor evaluations. BYOC and SPCS deployment options grow with organizational needs.
Openflow transforms data ingestion from an operational challenge into a strategic advantage: consolidating your stack while accelerating insights across your entire data landscape.
Ready to modernize your data ingestion strategy? Connect with Hakkoda’s data engineering experts today to discuss how Openflow can streamline your specific data sources and accelerate your analytics initiatives.


