

As the modern data stack expands across clouds and platforms, organizations face increasing complexity ingesting, transforming, and delivering data from a diverse range of sources: APIs, databases, SaaS platforms, event streams, and even spreadsheets. As a lead data engineer at Hakkoda, one of Snowflake’s elite consulting partners and an Openflow launch partner, I’ve seen firsthand the growing demand for native, secure, and scalable ingestion pipelines that reduce integration overhead and accelerate time to insight. Snowflake Openflow answers that call.
Launched as part of Snowflake’s latest platform evolution, Openflow is a managed, Snowflake-native data ingestion service designed to simplify and unify how data enters the Data Cloud. By combining the power of Apache NiFi with the security and scale of Snowflake, Openflow empowers data teams to create ingestion pipelines that are visual, flexible, and deeply integrated with Snowflake’s ecosystem.

What is Snowflake Openflow?
At its core, Snowflake Openflow is a visual, low-code orchestration engine for ingesting data into Snowflake. It provides a native interface within the Snowflake UI that allows users to define flows using prebuilt processors—without writing custom code or managing separate infrastructure.
Openflow supports a wide array of source types, some of which are:
- Streaming sources like Kafka and Kinesis
- Cloud storages/drives like Amazon S3, SharePoint where file-first data (typically unstructured) is hosted
- Relational databases like PostgreSQL, MySQL, and SQL Server
- APIs and cloud apps such as Workday, Google Sheets, MS Excel, and others.
The built-in connectors handle ingestion, parsing, transformation, routing, and delivery. These flows can be scheduled or triggered and monitored directly in the Snowflake console, tightly integrating with native services like Snowpark, Streams, and Tasks, and Cortex AI.
Openflow Architecture Overview
Openflow is powered by Apache NiFi under the hood, but abstracted to fit seamlessly within Snowflake’s control and execution layers.
Key architectural components:
- Control Plane (Snowflake-managed): Hosted within the Snowflake UI, this is where you build and manage your data flows using a drag-and-drop interface. It handles flow definitions, scheduling, permissions, and logging.
- Data Plane (AWS-hosted): Managed by Snowflake in a secure, scalable environment. This is where the data movement and transformation occurs using the NiFi runtime. Users need to provision this initially in AWS manually or using a CloudFormation template provided by Snowflake. Snowflake also has a Snowpark Container Services based data plane on the roadmap that will provide the infrastructural layer and further simplify the overall setup required to access runtimes.
- Connectivity Layer: Openflow supports connectors for dozens of systems, with secure credentials stored in Snowflake and role-based access control enforced consistently across the platform.
This architecture ensures Openflow remains both Snowflake-native and cloud-agnostic, with ingestion pipelines that are reliable, repeatable, and observable.
Reference Architectures for Openflow
Snowflake Openflow can slot into a variety of architectural patterns. Here are two prominent ones:
a. Medallion Architecture
Openflow is a powerful fit for Medallion-style data lakes, especially when data comes from streaming or API-based sources.
Example Flow:
- Bronze Layer: Ingest Kafka event streams or API data directly into Snowflake using Openflow. Apply minimal parsing or validation.
- Silver Layer: Clean, deduplicate, and enrich data using Snowflake Scripting, Snowpark, dbt, or any other transformation pattern/tool.
- Gold Layer: Serve data to BI tools or ML pipelines via curated tables or views.
The decoupling of ingestion and transformation allows for scalable, schema-flexible design patterns.
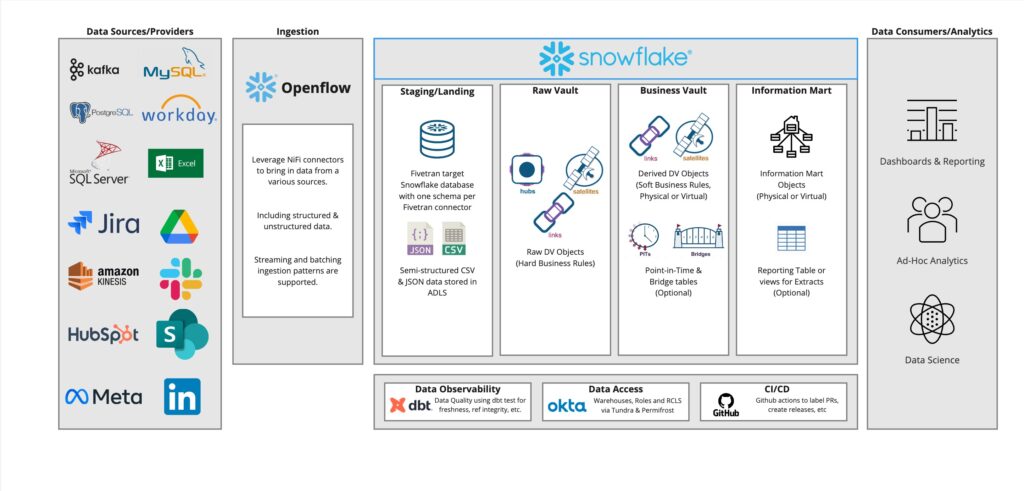
b. Data Vault Architecture
Openflow also supports Data Vault 2.0 implementations, which depend on consistent, auditable loading of data from multiple systems.
How Openflow fits:
- Pulls data from ERP, CRM, financial systems, and APIs.
- Routes raw data into staging tables with consistent metadata and timestamps.
- Enables orchestration of complex multi-system ingestion flows into a unified Snowflake warehouse.
This pattern benefits especially from Openflow’s lineage tracking, retry logic, and time-based scheduling capabilities.
Here’s a diagram that showcases a Data Vault reference architecture that fits Openflow as the main ingestion pattern:
Key Differentiators of Snowflake Openflow
While there are many ingestion tools on the market, Openflow offers several advantages by being native to the Snowflake ecosystem:
- Security & Governance: Leverages Snowflake-native roles, policies, and credentials. No need to manage secrets in external tools.
- Flexible deployment options: Snowflake offers customers two deployment models: BYOC (customer-managed VPCs) or SPCS (Snowflake-managed infrastructure and scaling). These models cater to diverse infrastructure management preferences.
Clear division of duties: Build, monitor, and troubleshoot ingestion pipelines in the Openflow Canvas aka Data Plane, and manage Data Plane deployments and look up available connectors through a single Control plane in Snowsight. . - Native Billing & Observability: Usage and costs are surfaced directly in Snowflake, alongside compute and storage.
- Developer-Friendly: Can be extended using scripting processors, and integrated with Streams, Tasks, and Snowpark workflows.
Demo: Ingesting Google Sheets into Snowflake
To demonstrate how simple Openflow can be, here’s a basic ingestion use case: Pulling a Google Sheet into Snowflake.
Scenario:
A corporate finance team maintains a Google Sheet that aggregates key financial forecast adjustments throughout the day, including updated revenue projections, expense estimates, or one-off event impacts. These adjustments are made by analysts across departments, and leadership needs to monitor changes in near real time to make timely decisions.
Instead of waiting for daily batch jobs, the data needs to be ingested into Snowflake every hour so that updated dashboards and models always reflect the latest inputs.
To set this up, we need to start by setting up a service account in Google Workspace, that will allow us to hit the Google Sheets API with requests to get the data periodically [2]. After this, in Snowflake, a table with the following columns has to be created: timestamp, adjustment_type, amount, currency, business_unit, reason, status, last_modified_by and last_modified_time. Once these prerequisites have been fulfilled, we can start working on the Openflow canvas. The final flow looks something like this:

The first processor is pulling data from the specified GSheet, it’s configured to run every 30 minutes, same as the rest of the flow. Processors 2 and 3 build the table in case it doesn’t exist and update the schema if necessary. Processors 4 and 5 truncate the table and insert new records. Processors 6 and 7 only get triggered in case of a failure in the third processor, they would try to create the table again or log the error in case of a failure. Processor 8 is a simple logging mechanism.
All processors are configured to retry each action 10 times before aborting completely. This is a very simple flow, with no transformations involved, only insertion into a table. The final result can be seen in Snowflake, as follows:

This flow runs serverlessly with full logging and retry support—without writing a line of code or spinning up infrastructure.
Final Thoughts
Snowflake Openflow is a milestone in the evolution of modern data ingestion. It bridges the gap between low-code usability and enterprise-scale data engineering, enabling both quick prototyping and production-grade pipelines.
At Hakkoda, we’re already seeing the impact Openflow can have on accelerating client solutions, especially for complex ingestion needs across regulated industries, multi-system integrations, and real-time analytics platforms.
Whether you’re building out a Medallion architecture, adopting Data Vault 2.0, or simply need to integrate third-party SaaS tools, Openflow provides a scalable, secure, and Snowflake-native solution.

Explore Snowflake Openflow With Your Own Data
Want to see Openflow in action?
- Explore the Openflow documentation on Snowflake
- Reach out to Hakkoda for support in designing or optimizing your ingestion pipelines. We’re here to help you unlock the full potential of your Snowflake Data Cloud.


