

Teradata to Snowflake Migration: Complete guide in 6 steps
The demand for moving data services from on-prem to the cloud has exploded. As a result, organizations are shying away from migrating straight Database Management Systems (DBMSs) to the cloud. Instead, they’re looking to engage data consulting partners to help them re-engineer those systems to the cloud.
But what forces are driving a Teradata to Snowflake migration?
|
Benefits of migrating from Teradata to Snowflake:
- A single source of truth
- Slashed data platform costs
- Built-in security
- Easy-to-enforce compliance and governance
- Instant, non-disruptive scalability
- Advanced analytics with artificial intelligence and machine learning
Yet, despite lower costs, greater elasticity, scalability, and consumption-based pricing, organizations aren’t strangers to Snowflake migration challenges. These typically include a complex transition, in-house skill gaps, tight budgets, and potentially high-risk migrations.
To assess your Snowflake migration readiness, consider the following:
- Transition & processes – Where do you start? What data do you migrate from Teradata to Snowflake? How do you put new processes in place?
- In-house skills – Does your team have the skills and experience to facilitate the migration from Teradata to Snowflake? Do they know how to maximize the power and value of Snowflake once workloads have migrated?
- Budget – You may have a tight budget. How do you prioritize the task? How do you ensure you’re migrating the workloads that can drive value?
- Risk – Do you have a proof of concept (POC)? What if your POC doesn’t pan out? Are you locked in?
- Security and governance – How do you migrate your data securely? How do you set up a data governance plan in Snowflake for long-term success?
| Maximize the value of your Teradata to Snowflake migration. Jump on a FREE consultation call with Hakkoda Snowflake experts. |
Contents
Step 1: Make An Execution Plan For Migration
Step 2: Move Your Database Structure
Step 3: Load Your Existing Dataset
Step 4: Transfer Data Pipeline and ETL Processes
Step 5: Turn Off Teradata
Step 6: Modernization
Need Help Migrating From Teradata To Snowflake?
Step 1: Make An Execution Plan For Migration
To tackle Snowflake migration challenges, you need a strategy. There are essentially two roads to take. Ask yourself:
1. Am I looking to deliver new value? If you’re looking to gain more value and modernize and monetize, then you will need to focus on prioritization.
- What’s the first step to moving over to Snowflake?
- How do I start to incorporate the Snowflake marketplace?
- It’s not about migrating a table. It’s reframing your thinking to “this set of data supports mission-critical reports and needs to go into Snowflake.” It requires envisioning how the consumers of the report will have a better experience.
- Am I looking to solve pain points? If your data takes too long to process and is unreliable, then Snowflake consulting services will be focused on pipeline management, automation, data governance, and cataloging. Pain points are technical pieces that end-users do not see, but are those that drive benefits when done correctly. Specifically, the intent is to lay the right foundation for innovation.
- What skills do I need in-house?
- What is a good proof of concept which will indicate if a migration is successful?
- How will the size of my daily workload be related to the cost of Snowflake, bearing in mind that this is less about how big your warehouse is and more about how much you process (in/out each day) and how many reports or data science models your warehouse supports?
- What about data cataloging? A good analogy is a library catalog. Anyone can “build a library” by buying shelves and putting books on them. But until you inventory and catalog which books are on which shelves and in what order, you won’t know what’s in your library (and what isn’t). The same holds true for your data.
Migrating to Snowflake is a lot like renovating a bathroom
Step 2: Move your database structure
Step 2.1 Pre-migration effort.
We consider database structure as all the components that reside in the databases you want to migrate to Snowflake. It could be just one database you want to migrate, or several separate databases you wish to migrate and join to create a single database in Snowflake.
Two related questions during this step are: How well do we define the scope of the database structure migration? And, what is the migration scope? The scope defines the boundaries of the migration efforts.
There are commonly database objects that we do not want to migrate as they exist in the current client databases. And there could be different reasons for not migrating them, for example:
- There is not a similar structure in Snowflake, like indexes, types, or triggers. And sometimes, there are specific schemas that were built only to handle indexes or collection of statistics. We may not want to consider those schemas in the migration scope, so we are not moving these types of objects to Snowflake since we have other approaches and structures within Snowflake to replicate their functionality.
- Nonrelevant database objects. Mainly in non-production environments, we have objects that were built to run POCs, or they are just outdated or deprecated. We may not wish to migrate or consider these objects as part of the new database structure in Snowflake.
- Duplicated structures. We could have patterns in our code. For example, suppose we have a database that handles client information. In that case, we may have the same structure for each of our clients, so we may elect to migrate just one client structure and recreate all the other clients’ databases using some accelerator scripts.
We have been talking about the migration scope because the best you can do in migration is reduce the scope.
Once you have your migration scope delimited in a migration inventory, the next step is defining the migration strategy. We have a lot of approaches, but let’s discuss three:
-
- Lift and shift: This approach consists of moving what you have in your current database to Snowflake without changing the objects or logic. This means that if you have 1548 tables in Teradata, you will have 1548 tables in Snowflake, with the same data types and column distributions. If you had 357 procedures and functions, you would have the same number of objects in Snowflake. This includes schemas, users, roles, permissions, security, and all the common database objects such as synonyms, tables, views, procedures, functions, and packages.
- What will happen with the objects I cannot migrate directly to Snowflake, like triggers, dblinks, and indexes? We will define takeaways for these objects, and we can use tasks and streams and reclustering methodology in Snowflake.
- Lift and shift: This approach consists of moving what you have in your current database to Snowflake without changing the objects or logic. This means that if you have 1548 tables in Teradata, you will have 1548 tables in Snowflake, with the same data types and column distributions. If you had 357 procedures and functions, you would have the same number of objects in Snowflake. This includes schemas, users, roles, permissions, security, and all the common database objects such as synonyms, tables, views, procedures, functions, and packages.
-
- Re-architecture: This approach will help when you do not want your new Snowflake database to look the same as your current database. This will imply that maybe not all the objects will be migrated as they are currently, so it is not going to be an apples-to-apples migration, instead, it could be like an apples-to-apple juice migration. We need to mention that these migration approaches will require building new data models and are typically used when organizations want to improve their database and data layers and the ways in which they use their data.
- Lift and shift and modernization: This is our hybrid approach. We can have subsets of database objects that can be migrated as they are, and some others that will require some improvement in the models or some redefinition.
Once we define the migration scope and approach, we are ready to define our prioritization of objects to migrate. We have two types of effort: the lift and shift effort, and the re-architecture effort. For both of them, we need to prioritize what we will deploy first to the client’s Snowflake database. It could be a schema approach, a data approach like Sales data structure first, and ingestion pipelines approach, or a subject area approach. Once we have determined the prioritization of objects to migrate, we can start work.
But before that happens, you might ask, how can my company do all this? This is where Hakkoda can help, and Snowflake as well. Here at Hakkoda, we can take care of all this effort for you, and we will run what Snowflake calls an MRA.
MRA stands for Migration Readiness Assessment, and it is basically 2 weeks of meetings with Hakkoda and Snowflake experts in the following areas:
- Code conversion
- Data migration
- Data ingestion
- Data validation
- Reporting and Analytics
After the MRA, we will receive some key deliverables from the Snowflake Professional Service Team that will help to define the migration scope, migration approach, and the prioritization of the objects to migrate.
Step 2.2 Migration effort.
To start moving objects in the lift and shift approach, we will use some accelerator tools. We have plenty of tools in the market right now. However, we work directly with the team of Code Migration of Snowflake. Snowflake has licenses over several tools to migrate from a database code syntax to Snowflake javascript or SQL syntax.
Using these tools, we can migrate tables, views, procedures, functions, synonyms, packages, and also some external code like BTEQ scripts. The key here is time: we want the code to be migrated as quickly as possible, so we can start moving data and connecting pipelines to have Snowflake as our new single source of truth.
These tools will migrate the objects even if there are differences in the engines. For example, in Teradata tables, you could find data types like GRAPHIC that will be migrated to VARBINARY, and this isn’t a problem since they are functional equivalents. We will take the same approach with Teradata functions. We will migrate functions from Teradata that do not exist in Snowflake to Snowflake functions with different names but with similar or the same functionality.
We know that Snowflake is not Teradata and Teradata is not Snowflake. However, we care about functionality, and if we can recreate any specific Teradata functionality in Snowflake we will do it.
Considerations while migrating from Teradata to Snowflake using a lift and shift approach.
Tables:
Snowflake table documentation: Creating tables in Snowflake.
Teradata table documentation: Creating tables in Teradata.
- In Teradata, the syntax for the tables is database.tablename, and in Snowflake it is database.schema.tableName.
- In Teradata, you have Multiset, Set, and Fallback options, as well as optional table-level elements like Global temporary, Volatile, Journal, Freespace, Data block size, Index, and Partition by. However, you do not have this option in Snowflake.
- Global temporary and a volatile table are now available in Snowflake. However, you also have Snowflake transient and temporary tables.
- The functionality of Teradata set tables is not supported in Snowflake. However, our consultants handle this issue using custom unique constraints in Snowflake. Teradata Multiset tables work as a normal table with Snowflake functionality.
- In Teradata, the primary/unique index constraint can be declared outside the create table statement, but in Snowflake, it should be inside.
- In Snowflake, you must declare the foreign constraints as an alter table statement.
- In Teradata, you have the ‘with check’ option in the foreign constraints, but in Snowflake, it is not supported as part of the syntax.
- In Teradata, you can create tables as other tables with data or with no data. Our consultants can replicate this functionality using Snowflake to create a table with several options: as select, using a template, clone, or like.
Example of table migration:
Teradata syntax:

Snowflake Syntax:
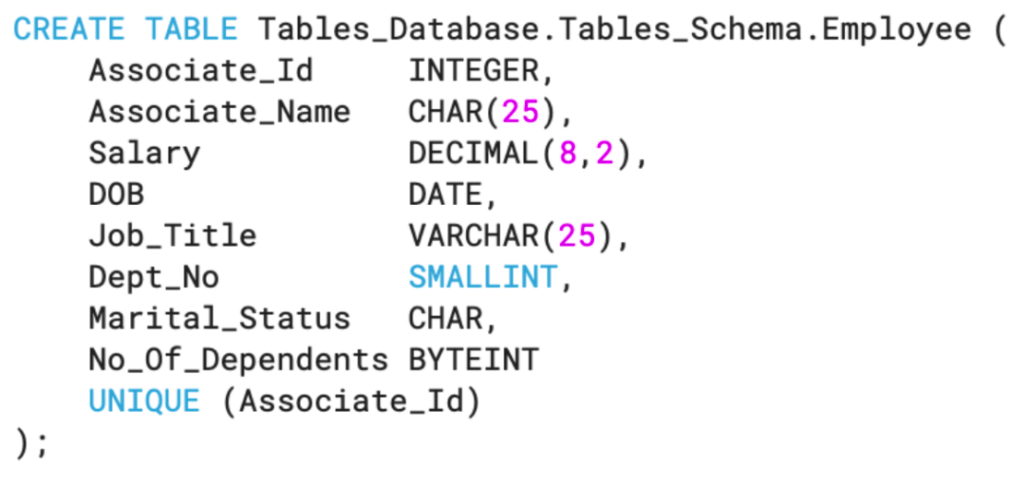
We can also consider the following table showing the differences in data types when you move from Teradata to Snowflake.
| Teradata data type | Notes | Snowflake Data type | Notes |
| CHAR | Up to 64k | CHAR | Up to 16MB |
| VARCHAR | Up to 64k | VARCHAR | Up to 16MB |
| LONG VARCHAR | Up to 64k | VARCHAR | Up to 16MB |
| BLOB | BINARY | ||
| CLOB | VARCHAR | ||
| BYTE | BINARY | ||
| VARBYTE | VARBINARY | ||
| GRAPHIC | VARBINARY | ||
| JSON | VARIANT |
This interesting blog provides some insights:
The following link provides an online free conversion tool from Teradata to Snowflake and allows you to play around with some DDL transformations:
Views:
There are two main differences when you create a view in Teradata vs Snowflake:
- We lose the ‘AS locking’ feature. Teradata As Locking in views
- The ‘Recreate View’ from Teradata changes to ‘Create or Replace View’ in Snowflake.
Functions:
In Snowflake, we have UDFs Snowflake UDF, so we can use them to replace Teradata functions, and we can write them using Java, Javascript, Python, and SQL.
Procedures, Macros, BTEQ, FastLoad, MultiLoad, TPT:
To migrate this to Snowflake we can re-engineer the logic and the processes using cloud technologies like DBT cloud, Python, and Matillion ETL, or we can also use Snowflake procedures with pipes, tasks, and streams.
Step 3: Load Your Existing Dataset
Once we complete the migration of the database structure, we can start the data migration.
To move data from Teradata to Snowflake we have several options in terms of technologies and connectors. But what really matters is what approach we are going to follow based on the data we have and the analytics environment we have or will build. We offer a bulk or a staged transfer of data approach.
What is Bulk and Staged moving?
Based on Snowflake migration Teradata to Snowflake Guide, we can define the considerations for when to use Bulk or Staged data move approaches.
You may choose to use bulk data transfer when you have:
- Data that are highly integrated into the warehouse.
- Data in independent and standalone data marts.
- Well-designed data and processes using standard SQL operations.
- Desire to move from legacy to Snowflake as soon as possible.
You may choose to use staged data transfer when you have:
- Independent or non-related data that can be migrated separately.
- Processes to re-engineer.
- New business requirements that are not aligned with legacy procedures.
- New additions in terms of business logic, tools, and pipelines.
A Bulk approach consists of moving everything with minimal changes using batch loading in Snowflake.
A Staged approach consists of moving by subject areas, data marts, or data groups in an iterative way so you can include changes and re-engineer some processes while you load data.
Data Validation
When you have defined the approach you wish to use, the next question is: How are we going to validate the data migrated? Hakkoda has accelerators that can help you resolve this issue. With accelerator tools, we can compare and validate data from the original database against the new Snowflake database using the conditions below:
- Validate the number of rows in tables.
- Calculate the sum, max, min, and avg of every column to check if we are getting the same number and to ensure information is not lost.
- Hash row values to compare if we can have a one-on-one association in both databases.
- Select subsets of data to compare based on date times.
Step 4: Transfer Data Pipeline and ETL Processes
In the transfer process, we have the opportunity to modernize how we ingest data and what tools we use to run and monitor our ETL. We can migrate everything to cloud technologies and, where required, we can keep some on-prem for source systems cloud compatibility or law regulations.
In order to do this, we carry out an analysis of each pipeline, looking for patterns. Once we have identified the patterns, we develop the recommendations and architecture proposal, beginning with the definition of technologies, approaches, and modernization opportunities.
Hakkoda will migrate everything to the new ETL architecture in parallel to the legacy client environment to allow one-on-one validation. This means that using the same source, we will ingest the Teradata system and Snowflake system, so we can compare and identify performance improvements, transformations missing, and maybe data leaks. The strategy to validate this ETL migration will be the same approach that we use for the data migration, but we will consider performance checks so we can improve timing and costs.
Step 5: Turn Off Teradata
Our recommendation is to run parallel systems for a time. Running in parallel means we can compare in real time the new Snowflake environment against the old environment. Having the same report pointing to both environments means we can validate and check that data is correct at a given moment.
Once we have moved all client subject areas or data sets and their dependencies to the new Snowflake environment, and have validated the environment, at that point we can turn off Teradata and just run Snowflake with the dependencies fully migrated to Snowflake.
Step 6: Modernization
At this point, we are up and running in Snowflake with a world of opportunities and advantages available to your organization, such as:
- Pay as you go in terms of compute and storage and the ability to manage these costs separately.
- A completely cloud-based data service.
- Access to the Snowflake data marketplace.
- Access to a complete partner ecosystem that creates and supports Snowflake.
- New visualization tools like Sigma to run on top of Snowflake.
- Data governance.
- The best definition of security policies, data access, and data replication.
- Implementation of ML, improved pipelines, modernized technologies, and best practices in your environment.
What is the next big thing you want to do?
Whatever your answer is, Hakkoda is ready to help you. We are ready to scale our team up or down based on your requirements.
Need Help Migrating From Teradata To Snowflake?
Have questions? Want to go deeper into Teradata to Snowflake migration? Our data experts are here to help. Get in touch.
Additional resources:
Complete migration from Teradata to Snowflake guide: https://resources.snowflake.com/migration-guides/teradata-to-snowflake-migration-guide#main-content


