

Most organizations have accumulated a collection of data tools and projects, but lack true data products.
The difference matters: data products have clear ownership, defined users, measurable impact, and compose together to create exponential value.
This product-centric approach transforms data teams from project executors into value creators, regardless of your underlying architecture.

The Real Problem: Partial Platforms and Scattered Projects
If you’re a data leader today, you likely have substantial infrastructure: a cloud data warehouse or lakehouse, multiple ingestion tools, transformation pipelines, BI platforms, and perhaps some ML capabilities. You’ve invested millions in technology and headcount.
Yet something feels incomplete. Data projects land on your platform, but they don’t connect. Each initiative seems to start from scratch. Knowledge doesn’t transfer. Value is hard to measure. Teams are perpetually busy but business impact remains elusive.
The issue isn’t your platform. It’s that you have a platform for projects, not products.
Projects have endpoints. Products have lifecycles. Projects are delivered once. Products evolve continuously. Projects satisfy requirements. Products create ongoing value for defined users.
The organizations winning with data have made a fundamental shift: they’ve stopped thinking about data projects and started building data products.
The Reductionist View: Simplifying Complexity
Let’s start with a principle from systems thinking: the Law of System Reduction. Every system, no matter how complex, can be reduced to a series of inputs and outputs. This elegant simplification cuts through the confusion that often surrounds data initiatives.
Applied to data work, this means:
- All data-related work results in a data product
- Every data product is itself a system
- Every system can be decomposed into its constituent parts
- Each part has clear inputs and outputs
This reductionist view works regardless of your architectural choices. Whether you’re building a lakehouse, maintaining a traditional enterprise data warehouse, or implementing a hybrid approach, the principle holds. You’re creating systems that transform inputs into outputs, and those systems are your data products.
Data Products as Building Blocks: Composability and the Dependency Graph
Here’s where it gets powerful: data products compose. They don’t exist in isolation. They form a dependency graph where one product’s output becomes another’s input, creating network effects similar to microservices architecture or the enterprise service buses of the past.
A data product can be elegantly simple or richly complex:
Simple Product: Raw healthcare claims data → Cleaned, validated claims model
Intermediate Product: Multiple EHR sources → Integrated patient longitudinal record → Clinical dashboard
Complex Product: Patient records + Claims data + Social determinants → Readmission risk model → Care management application
Additionally: Integrated patient model → Reverse ETL → EHR system (closing the loop with enriched insights)
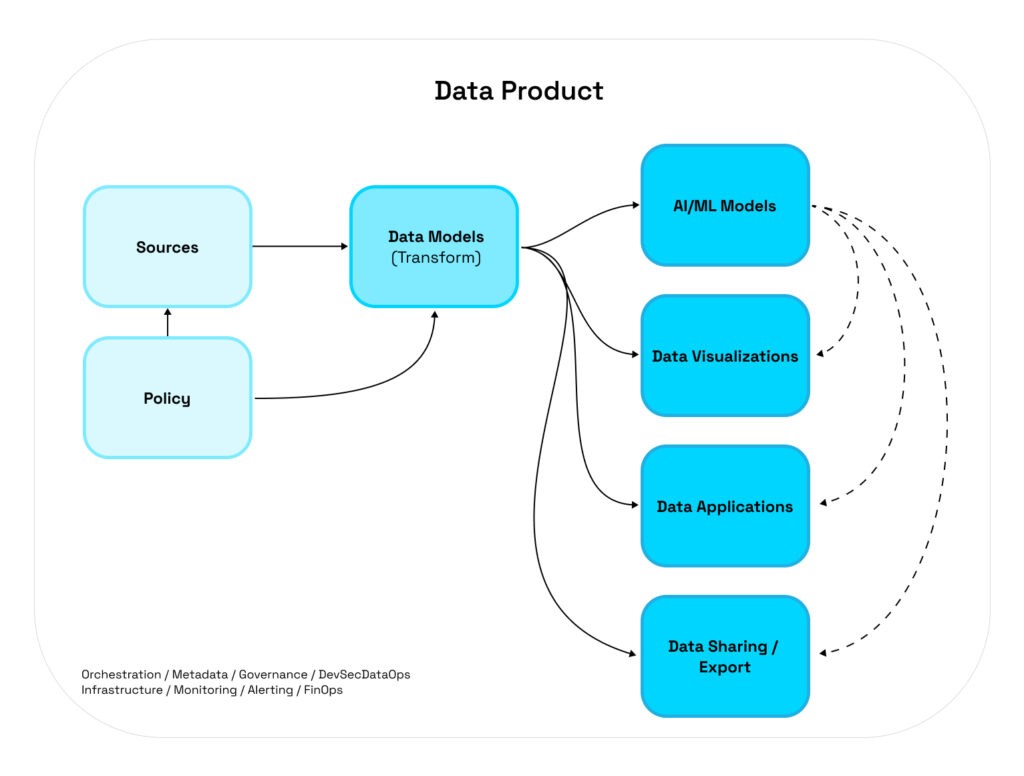
The beauty of this composability is strategic: you can start small and build up. You don’t need to deliver the full stack at once. Begin with a single well-governed data model. Prove its value. Then build products that consume it. Those become inputs to even more sophisticated products. Value compounds.
This is fundamentally different from the project mindset, where each initiative is a one-off effort. With composable data products, each new product leverages and amplifies the value of existing ones.
Data products naturally align with domain boundaries. In healthcare, this might mean clinical operations owns patient care coordination products, revenue cycle owns billing and claims products, and population health owns risk stratification products. Each domain develops deep expertise in their data and the problems they’re solving, while the platform provides the infrastructure and standards that allow these domain products to compose together. This domain-driven approach prevents the bottleneck of a centralized team trying to understand every nuance of every business area.
What Makes Something a Data Product?
Not every dataset or dashboard qualifies as a data product. True data products share five essential characteristics:
1. Clear Product Ownership
Every data product needs a product owner who:
- Defines and prioritizes features based on user needs
- Manages stakeholder relationships and expectations
- Measures and communicates value
- Makes trade-off decisions between competing priorities
- Owns the product roadmap and evolution
This isn’t a project manager checking tasks off a list. It’s someone accountable for ongoing value creation.
2. Defined Personas
You must deeply understand who uses your data product and how. Common personas include:
- Clinical executives (healthcare): Need population health metrics and quality measure dashboards
- Care coordinators (healthcare): Require patient risk scores and intervention recommendations
- Analysts: Need self-service exploration capabilities
- Data scientists: Require access to refined datasets for advanced modeling
- Operations teams: Need real-time alerts and actionable insights
- External partners: May need embedded analytics or data subscriptions
Each persona has different needs for latency, granularity, interface, and support. Generic “one size fits all” data assets fail because they serve no one well.
3. Release Cycles & Versioning
Data products evolve like software products:
- Version control for models, schemas, and business logic with clear communication about what changed and when
- Backward compatibility planning when changes occur
- Clear communication about deprecated features
- Documented change logs that users can reference
This discipline transforms ad-hoc “fix it when it breaks” approaches into predictable, professional service delivery.
4. Established SLAs
Service Level Agreements define expectations around:
- Data freshness: Daily batch? Hourly? Real-time streaming?
- Availability: What’s the uptime guarantee?
- Data quality: What accuracy, completeness, and validity standards apply?
- Support response times: How quickly are issues addressed and resolved?
SLAs create accountability and allow users to design their workflows around reliable service delivery.
5. Measurable Impact
This is where strategy becomes tangible. Every data product must have clear metrics that demonstrate value. These aren’t vanity metrics like “number of reports created” or “data volume processed.” They’re business outcomes.
The specific metrics depend on the data product category, hypothetical examples:
Analytical Products (decision support):
- Value against baseline: A demand forecasting model that reduces inventory costs by 12% compared to previous manual methods
- Stakeholder-reported value: Revenue cycle analysts report $2M in recovered revenue annually
Operational Products (workflow enhancement):
- Hours saved: Automated patient scheduling that saves care coordinators 15 hours per week
- Risk avoided: Predictive sepsis alerts that reduce adverse events by 8%
Customer-Facing Products (revenue-generating):
- Direct revenue: A benchmarking analytics platform sold to health systems generates $500K in Annual Recurring Revenue (ARR)
- Retention impact: Provider network adequacy tools reduce client churn by 18%
The common thread: every product must answer “what business outcome does this create?” with a measurable response.

Measuring Platform Success: Beyond Individual Products
While individual data products have their own KPIs, the platform that enables them needs its own metrics:
- Platform Performance: How quickly can you provision environments and deploy products? Target minutes and days, not weeks and months.
- Platform Economics: What’s your total cost of ownership and cost per product? Are you getting more efficient over time?
- Platform Health: How much downtime are you experiencing? Track incidents, detection time, resolution time, and quality scores.
These platform metrics tell you whether your foundation is solid enough to support growing product development.
Getting Started: The Highest-Impact Moves
Theory is valuable, but action creates change. Based on patterns across successful implementations, three areas deliver the highest immediate impact:
1. Standardize Ingestion Patterns
Most organizations have multiple teams solving the same ingestion problems differently. Consolidate around reusable patterns for:
- API integration: How do you reliably consume third-party APIs (payer data feeds, lab results, pharmacy claims)?
- Database replication: What’s your standard approach for EHR, billing, and other transactional systems?
- File-based ingestion: How do you handle the inevitable CSV files from legacy systems?
- Real-time streaming: When you need sub-minute latency, what’s the pattern?
Document these patterns. Build templates. Make it trivially easy for teams to ingest new sources correctly the first time.
2. Implement a Data Catalog
You can’t manage what you can’t see. A proper data catalog (modern SaaS solutions work well here) provides:
- End-to-end lineage from source systems through transformation to consumption
- Business glossaries that bridge technical and domain language
- Impact analysis that answers “what breaks if I change this?”
- Self-service discovery that reduces the “where do I find X?” questions
Note: Transformation tools like dbt provide some cataloging, but only for what they transform. You need comprehensive visibility across your entire data platform.
3. Consolidate Transformation Approaches
Scattered transformation logic (some in ETL tools, some in stored procedures, some in Python scripts, some in BI tools) creates fragility and knowledge silos. Standardize around:
- A primary transformation framework (dbt is the current standard, though no-code/low-code tools like Coalesce are effective for many teams)
- Testing and quality gates before production
- Code review practices
- Documentation standards
This isn’t about religious adherence to one tool. It’s about creating consistency that allows knowledge transfer and reduces cognitive load.
Beyond the Basics: Advanced Data Product Patterns
Once you’ve established foundational capabilities, several advanced patterns unlock disproportionate value:
Reverse ETL: Push refined insights back to operational systems (EHR, CRM, care management platforms) so insights drive action in existing workflows rather than requiring separate tools.
Embedded Analytics: Rather than forcing users to context-switch to BI tools, embed analytics directly into the applications where work happens.
Data Marketplace: Create internal (or external) marketplaces where well-documented, high-quality data products can be discovered and consumed with clear SLAs and pricing models. When properly curated, a marketplace can function as a semantic layer, allowing business questions to be answered by navigating product metadata and outputs rather than querying raw data directly. This abstraction means insights can be gathered from the marketplace catalog itself, making data discovery and consumption more intuitive for non-technical users.
Advanced Analytics & AI: For predictive and prescriptive use cases (demand forecasting, risk scoring, recommendation engines), AI and ML unlock significant value. But here’s the critical point: AI is only as good as the data foundation beneath it. LLMs and generative AI tools require high-quality, well-governed data to avoid hallucinations and deliver reliable insights.
The recent wave of AI agents (like OpenAI’s AgentKit and similar frameworks) makes this foundation even more critical. AI agents automate complex workflows by chaining together multiple actions and decisions. Without reliable data products feeding these agents, you risk amplifying data quality issues at scale. Your data products become the training ground and operational fuel for AI initiatives, making the difference between AI agents that add value and those that create new problems.
The Mindset Shift: From Order-Takers to Value Creators
Ultimately, treating data as products fundamentally changes how data teams operate:
Project teams respond to requirements, deliver once, and move on.
Product teams understand users deeply, deliver iteratively, measure impact rigorously, and improve continuously.
Project teams ask “what do you want built?”
Product teams ask “what outcome are you trying to achieve?”
Project teams measure completion.
Product teams measure value.
This shift works regardless of your underlying architecture. The principles (composability, clear ownership, defined users, measurable impact) apply whether you’re on Snowflake or Databricks, using dbt or Spark, deploying to AWS or Azure or GCP.
The platform enables the products. The products deliver the value. Both matter, but never lose sight of the fact that the ultimate goal is business impact, not infrastructure elegance.

Conclusion: Start Building Products, Not Just Projects
The organizations that will win in the next decade of data won’t necessarily have the biggest platforms or the most advanced technology. They’ll be the ones who’ve mastered the art of building, scaling, and governing data products that create measurable business value.
You likely already have substantial platform capabilities. The opportunity isn’t to rip everything out and start over. It’s to shift how you think about and organize the work that happens on that platform.
Start small. Pick one high-value use case. Apply the product lens: clear ownership, defined personas, SLAs, measurement. Build it as a composable component that others can build upon. Prove the value. Then scale the approach.
The dependency graph grows. The network effects compound. The platform evolves from a cost center to a value engine.
Ready to transform your data initiative into a product-driven organization? Your platform investments have created the foundation. Now it’s time to build products that deliver exponential value. Let’s talk about how to make that shift in your organization.
Reach out today to begin your data product journey from strategy to implementation to ongoing optimization.


