

Data science models are a powerful way of applying statistics to business challenges in order to increase efficiency, mitigate risks, reduce costs, and raise revenues. Inside of many organizations, however, there is a sizable gap between building these models and moving them to a production environment where businesses can use them to make data-driven decisions. Fortunately, emerging technologies like Snowflake MLOps are now giving businesses the tools they need to close these gaps and leverage their data science models faster than ever before.
Traditionally, moving data science solutions to the production stage meant writing them into a software or SaaS solution, where models are stored on a cloud computing platform and called using a customized UI. This handoff between a data science team and software development team inevitably extended development time and complicated the process of turning data into actionable insights. In a world where such insights are a high-value competitive advantage, long delay times between data collection and analysis can cost an organization the edge it needs to survive.
A Faster Approach to Building and Deploying Data Science Models
Snowflake streamlines the build-to-production timeline by providing developer tools that enable analysts to swiftly and effectively build production-ready data science solutions that work within the Snowflake ecosystem. The Snowpark API enables developers to read and write data to Snowflake databases using SQL statements natively within Python. This makes working with complex data and sharing it with other analysts significantly easier, as it eliminates the need to share data or credentials to cloud platform instances.
User Defined Functions (UDFs) similarly enable developers to wrap Python and SQL models in a callable format that can easily be shared between users or called within Snowflake tasks in the case of scheduled runs. Python worksheets within Snowflake make this process even more unified, allowing users to write Python functions which directly interface with Snowflake data and live within the Snowflake UI. Finally, the recent announcement of Snowflake Native Apps enables analysts to quickly build an attractive user interface which interacts with any model built and defined in Snowflake.
The aggregation of these tools allows analysts to build a model and productionalize quickly, even without a strong background in software development. These features promise to solve many of the main pain points of data science while expediting the journey from data collection, to analysis, to evidence-based decision making.
Empowering Data Scientists with Snowpark
Historically, an analyst looking to share their data model with a colleague would be required to share a code repository and separately share access to a data source depending on size. As data volume expands, this process becomes increasingly cumbersome, and, even once the data sources and repositories are shared, the analyst receiving the model must still make alterations to account for any system differences before finally executing the code.
Implementing Snowpark into data science code allows analysts to point their models at the most up-to-date version of the data, avoiding any confusion about the single source of truth. This also enables analysts to grant access to a code repository that other analysts can access by simply entering their personal Snowflake credentials.
At the production level, implementing this same code into an orchestration tool like dbt or Airflow takes a fraction of the time, since a script can be quickly dropped into one of these tools and the data is automatically read in as long as credentials are configured accordingly.
The takeaway from either of these examples is that Snowpark can reduce the time and energy required to take a model from the development stage through to its ultimate distribution or operationalization.
Using Streamlined Data Science Models to Drive Business Outcomes
For non-technical users, the downstream benefits of Snowpark on data science models might be less clear. As stated above, Snowpark and its integration into other tools has the potential to significantly expedite the process of distilling your organizations’ data into the game-changing analytical insights that will propel your business forward. The introduction of tools like Sigma or Streamlit, meanwhile, are extremely accessible ways for data scientists to quickly build frontends for their model output: empowering data scientists with efficient, time-saving, and easy-to-use tools for parsing data at scale.
For enterprise decision makers, decreasing the time lost between data collection, modeling, and interpretation can mean the difference between a reactionary approach to tectonic shifts in the marketplace and the ability to anticipate and adapt to industry changes in advance.
Client Success Story: Modernizing Legacy Data Science Models with Snowflake MLOps
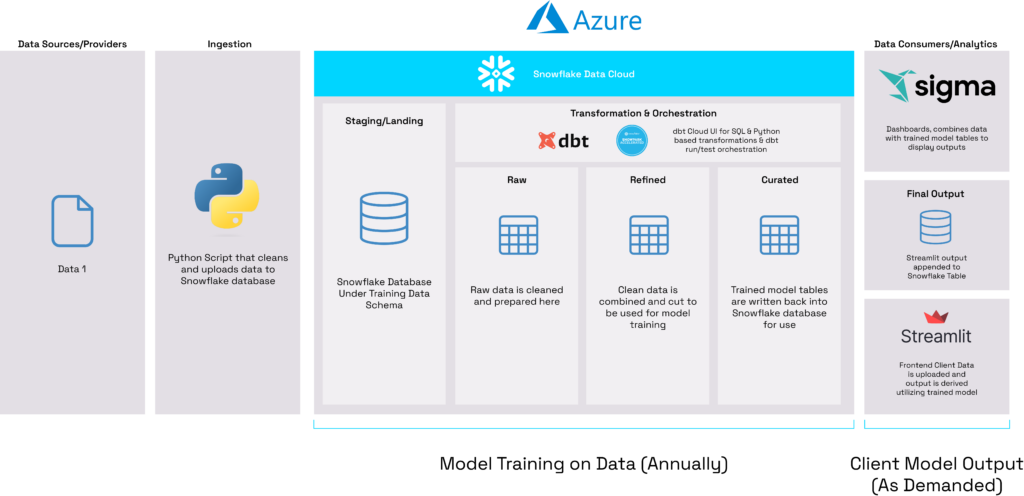
To further illustrate the far-reaching impact of Snowflake MLOps on businesses, consider the case of one of Hakkoda’s healthcare clients, faced with many of the same data modeling challenges outlined above. This client had previously built a strong data science model in the R programming language with data from 2018, but encountered significant obstacles when it came to sharing and deploying their model. The model was written off of R and had to be run and executed locally, requiring any user to download and configure the R programming language before executing the model in the command line in order to run it. For any non-technical user, this required them to have an engineer walk them through downloading and configuring the code. To make matters worse, if an update was made to the code or the data changed, this process had to be repeated for all users with access across the entire company.
Hakkoda understood that this client needed their data science model to be easily accessible for any user in the organization, which would allow it to be demoed to prospective clients or used to help existing clients make crucial decisions about their businesses. The tool also needed to be easily used by non-technical users without downloading or compiling code while always referencing the most recent version of the data without having to update all users when a change was made. Snowpark, written within Python code, offered a straightforward solution to this conundrum. Once hosted on a cloud platform, the code would always reference the most recent version of the data without requiring non-technical users to download large datasets to their machines. Additionally, hosting an easy-to-use frontend would enable any analyst in the company with proper access to navigate to a webpage and quickly access the tool for any purpose.
Two analysts from Hakkoda ported the entire model from R to Python and reworked data references to function exclusively within the Snowpark API. They then hosted the training of the machine learning model on a data orchestration tool called dbt Cloud, where it could retrain the model on new data independent of any single analyst. In order to increase the ease of access of the tool for employees within the firm, Hakkoda’s analysts built a client data entry tool on a service called Streamlit, which allows data scientists to build user-friendly websites using nothing but Python–removing the need for HTML, CSS styling, or web hosting. Finally, output from the model was written to Snowflake using Snowpark and referenced by a business intelligence tool where any analyst could manipulate and display the data.
The beauty of this approach is that it means the data science solution can be easily accessed by any user in the organization using two web links while not exposing anything “under the hood.” This not only increases ease of use for analysts, but presents a higher level of professionalism to clients who want to ensure that data models are presenting accurate, up-to-date information. This process took two analysts at Hakkoda roughly three months and transformed the way that this client built and presented data science models to its partners, who would depend on the accuracy and legibility of this data to save patient lives.
The Future of Data Science Models in Healthcare
Deploying data science solutions to a platform where they can be quickly and reliably applied to actual use cases is still a considerable challenge for many organizations. That said, native apps and the way that they interface with the Snowflake platform are blazing the trail for a brighter future in this regard: promising the ability to quickly develop and deploy data science solutions without duct-taping several tools together. The recent integration of Streamlit, meanwhile, opens up the possibility of an end-to-end solution where data scientists can write a model and deploy a front-end UI in minutes for less technical users or demo purposes.
While many of these tools are still in early development, the speed with which they have moved from their announcement to public availability suggests a high rate of early adoption. Feature sprawl, meanwhile, remains minimal at the present moment, making this an opportune time for businesses to begin Snowflake migrations.
Reimagining Data Science with Hakkōda
Hakkoda’s team of highly-trained experts is ready to bring our deep knowledge of emerging tools and technologies to help you take the plunge and move to a modern data stack. We leverage scalable teams of empathetic data architects, engineers, and scientists to build flexible, cost-saving data solutions that suit your business’s objectives, eliminating obstacles along your path to your next innovation.
Ready to start your data innovation journey with state-of-the-art data solutions? Speak with one of our experts today.


