

When a recent Hakkoda client working in global and domestic disaster relief looked at its legacy tech stack, they noticed it wasn’t performing the way they needed it to and identified several challenges that kept them from realizing the full potential of their data.
With the help of Hakkoda, the client rebuilt their end-to-end data pipelines using a Fivetran, dbt, and Snowflake analytics stack.
Challenges with Their Legacy System
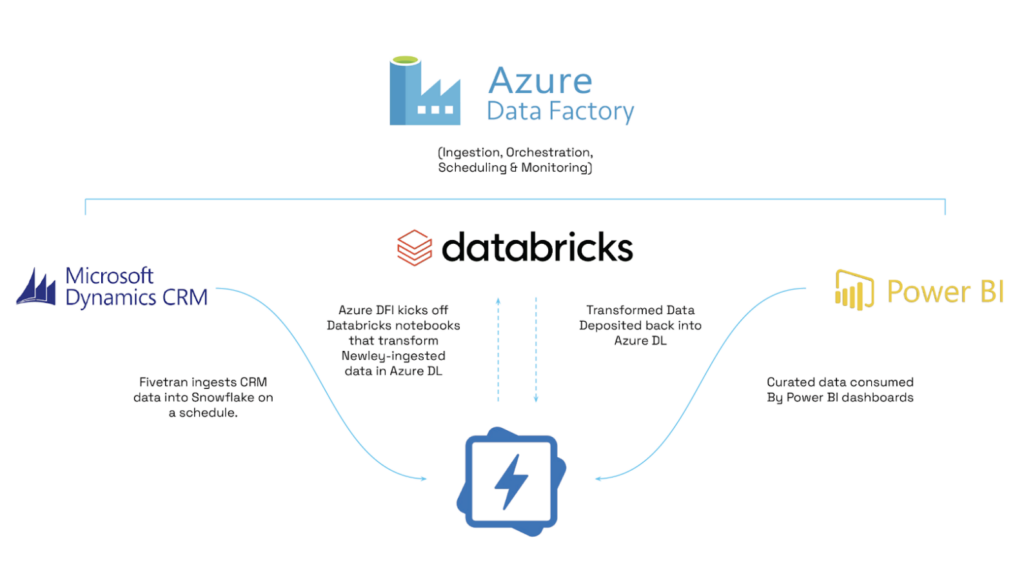
The client was using Azure Data Factory, Azure Data Lake, and Databricks for their data analytics stack. The challenge was that the source data was being ingested by Azure Data Factory from Microsoft Dynamics CRM and stored inside Azure Data Lake. This data was then accessed by Databricks, where data was transformed, joined, and curated before depositing back inside the data lake.
Several pipeline errors occurred, entire output tables had to be overwritten with the addition of data, and table joins and/or transformations were repeated in different Databricks notebooks within each pipeline, incurring unnecessary compute costs. And when there was a pipeline error, the Azure Data Factory details of the error code were difficult to interpret.
Fivetran, dbt Cloud, and Snowflake to the Rescue
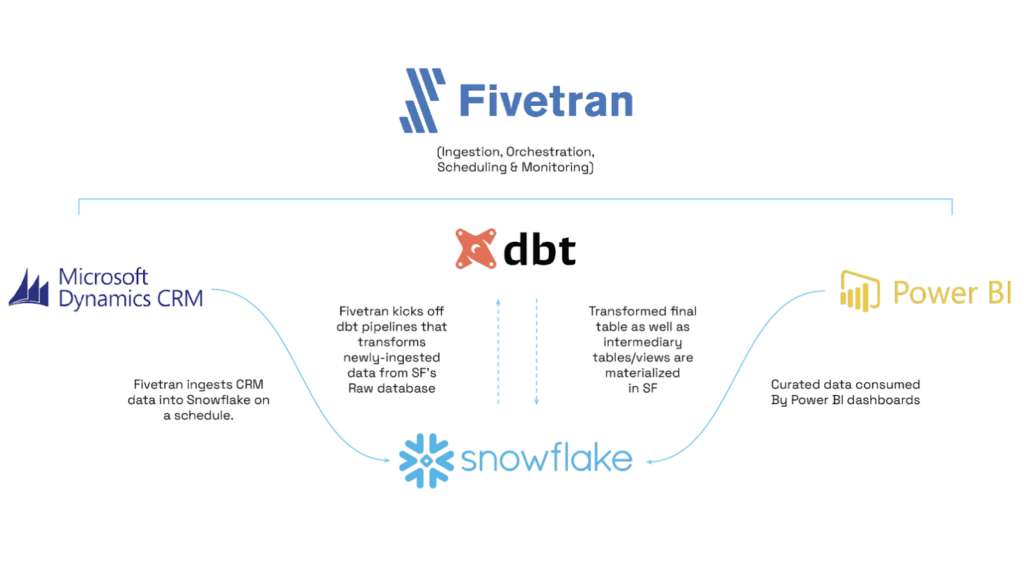
Hakkoda overcame the client’s challenges with their legacy analytics stack by using dbt for data transformations and Fivetran for ingesting source data and deploying the dbt models in production. A comparative analysis between the legacy and the new dbt-centered data stack shows that, with the latter, the average pipeline runtime has decreased by 60% overall.
On top of the reduction in pipeline runtime, dbt also makes it easier to debug errors. dbt logs clear error messages when a pipeline fails, and points to which model(s) is failing. One can then inspect the failing model(s) and see if there’s an immediate fix based on the type of error.
How dbt Reduces Data Pipelines Run Time
Because the client organization can modularize its data transformations into data models in a lineage with dbt Cloud, it can perform a join or a transformation in one model. Then downstream models can consume it without having to perform that same join/transformation again.
For our dbt solution, we structured the models into three layers, as shown below:
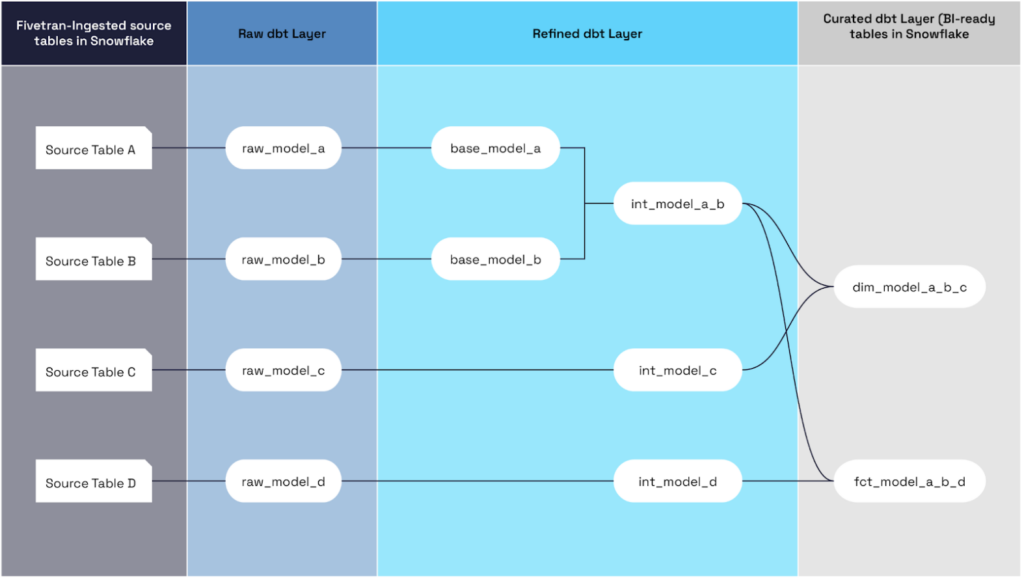
The raw layer contains the models that are one-to-one with the source tables, with minimal changes made to them. In other words, the raw tables are simply created by doing ‘select * from’ on the source tables. The second layer is the refined layer. This is where the core joins and transformations happen. Two different naming conventions are used for the models inside the refined layer: base_ and int_. Base models contain transformations, including column renaming, field creation using case/end statements, etc. Int (Intermediate) models combine two or more of the base models.
Finally, the curated layer contains dbt models that are materialized as tables in Snowflake, which are then consumed by a BI tool (PowerBI, in the client’s case). Note that in the flowchart above, the models ‘base_model_a’ and ‘base_model_b’ only need to join once to create ‘int_model_a_b,’ which is then joined by ‘base_model_c’ and ‘base_model_d’ to create final curated models ‘dim_model_a_b_c’ and ‘fct_model_a_b_d.’ This, therefore, saves pipeline runtime and hence the use of compute resources.
In addition to modularized data transformation(s), incremental models were used in the pipelines to help reduce the pipeline runtime. In this context, ‘ incremental’ refers to a specific way of materializing dbt models in Snowflake. Take ‘int_model_a_b’ from the flowchart above as an example. Assume that it had been configured as an incremental model.
Every time ‘int_model_a_b’ is run, only the newly-added records (since the last run) in ‘base_model_a’ and ‘base_model_b’ will be joined and appended to ‘int_model_a_b’ (instead of joining the entire table of ‘base_model_a’ with ‘base_model_b’ and overwriting the existing ‘int_model_a_b’ table in Snowflake). Since this limits the amount of data that needs to be transformed, it reduces the pipeline runtime and compute costs.
Continuous Innovation
Hakkoda’s disaster relief client needed to achieve data immutability (where information within a database cannot be deleted or changed, only added). To do that, Hakkoda implemented a feature in dbt called Snapshot. Snapshotting preserves the history of the changes made to a table, including the timestamps of when those changes occurred. This helps ensure that changes that should not be made to certain columns in a table are detected and corrected.
For instance, for a client project, if the status has previously been marked as Completed, it should never be changed to a different status, such as Active or Demobilized. Therefore, if someone accidentally makes that change inside Dynamics CRM, Hakkoda’s custom query will detect it in the pipeline as it checks against the snapshot table. Then it will prevent this change from taking effect in the final table and prevent it from showing up on the PowerBI dashboard.
If you face challenges with your legacy analytics system, Hakkoda can help. Not only are we a Snowflake elite partner, but we are also Snowflake’s Americas Innovative Partner of the Year. Our commitment to the modern data stack allows us to deliver business-driven narratives that solve critical challenges. We think outside the box and help develop unique solutions to your data analytics needs. Are you ready to learn more? Speak with one of our experts today.


